This is a somewhat detailed post regarding the variance plane, its scaling, and the effect on subsequent measurement errors. It is quite long so thank you in advance for any interest.
We are joint processing VISTA and HSC imaging in preparation for Rubin. The standard multiband pipeline requires a consistent pixel scale which effectively means warping the native 0.336 arcsec/pixel VISTA images to the higher resolution 0.168 HSC arcsec/pixel pixel scale. This makes the VISTA imaging subject to significantly higher pixel covariance. That said, my questions are relavent to the native scale pipelines due to the general warping process and interpolation.
In the standard run, as I understand it, the variance plane of the final coadd is scaled by the ScaleVarianceTask such that the median variance is equal to the coadd image pixel variance. Using this standard method we find that measured aperture magnitude errors are offset from those measured on the native scale using SExtractor by a factor of around 4. We are weighing up two possible mitigation strategies:
Firstly, we are considering simply scaling the measured catalogue errors to account for this offset. This is what has been done in previous studies using SExtractor in dual image mode on VISTA and DES imaging (Banerji, et al. MMRAS 446.3, 2015).
Secondly, we are considering measuring the image autocorrelation matrix. The sum of the normalised matrix should then give us the relative factor of variance lost to covariance. By scaling the whole variance plane according to this factor the various measurement algorithms should have their error measurements scaled.
The first is certainly simpler partly because it only involves post processing of the catalogues. It also should mean that pixel variances are appropriate for performing signal to noise detection thresholds on pixels. I am also nervous that the latter depoends on the assumption that all measurement algorithms will be similarly impacted by covariance which seems questionable.
In the long term a pipeline with multiple pixel scales would have advantages. Presumably given the large differences in resolution with, eventually, Euclid will necessitate such a new pipeline. For now we would like to work with a consistent pixel scale.
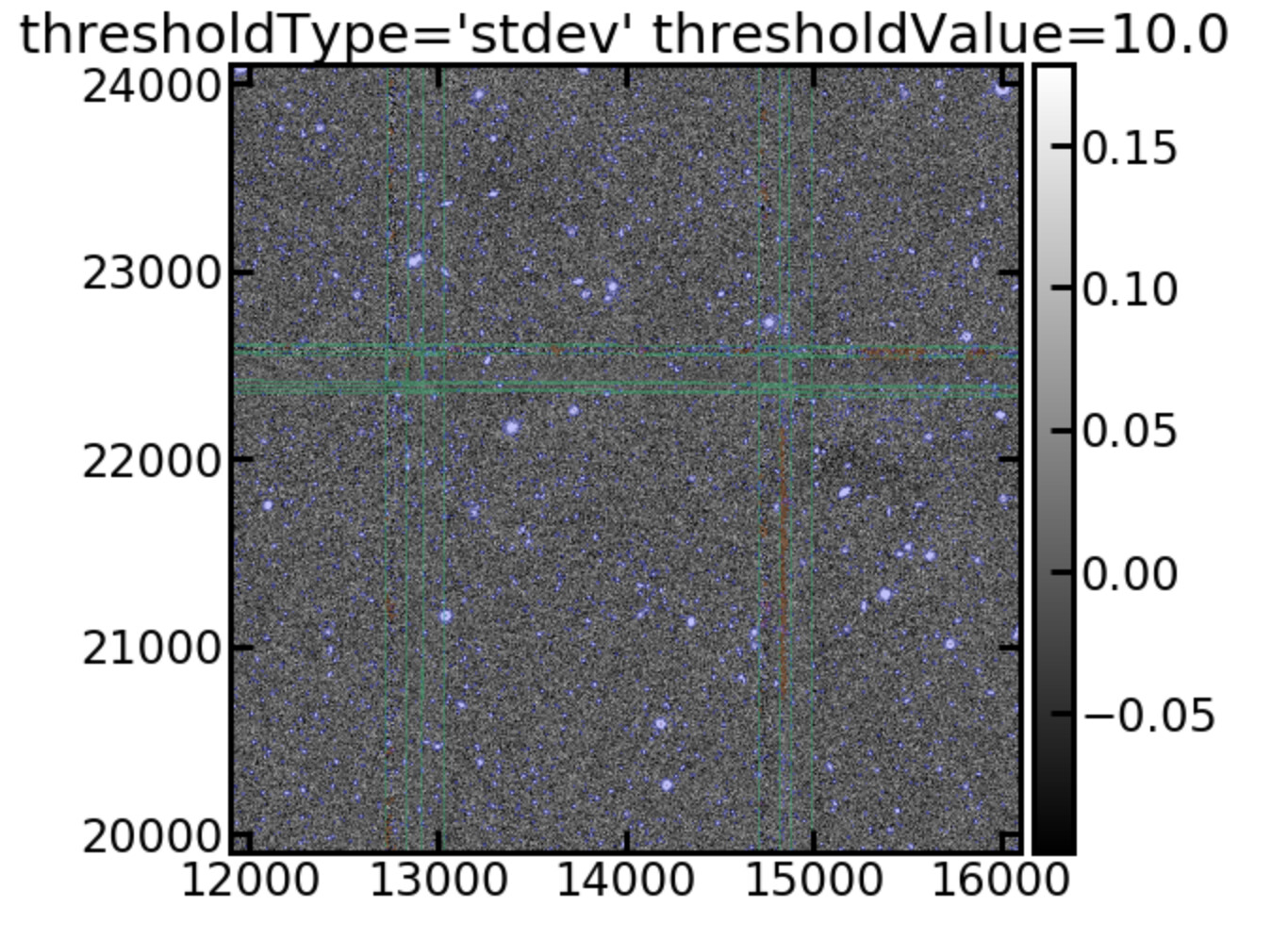
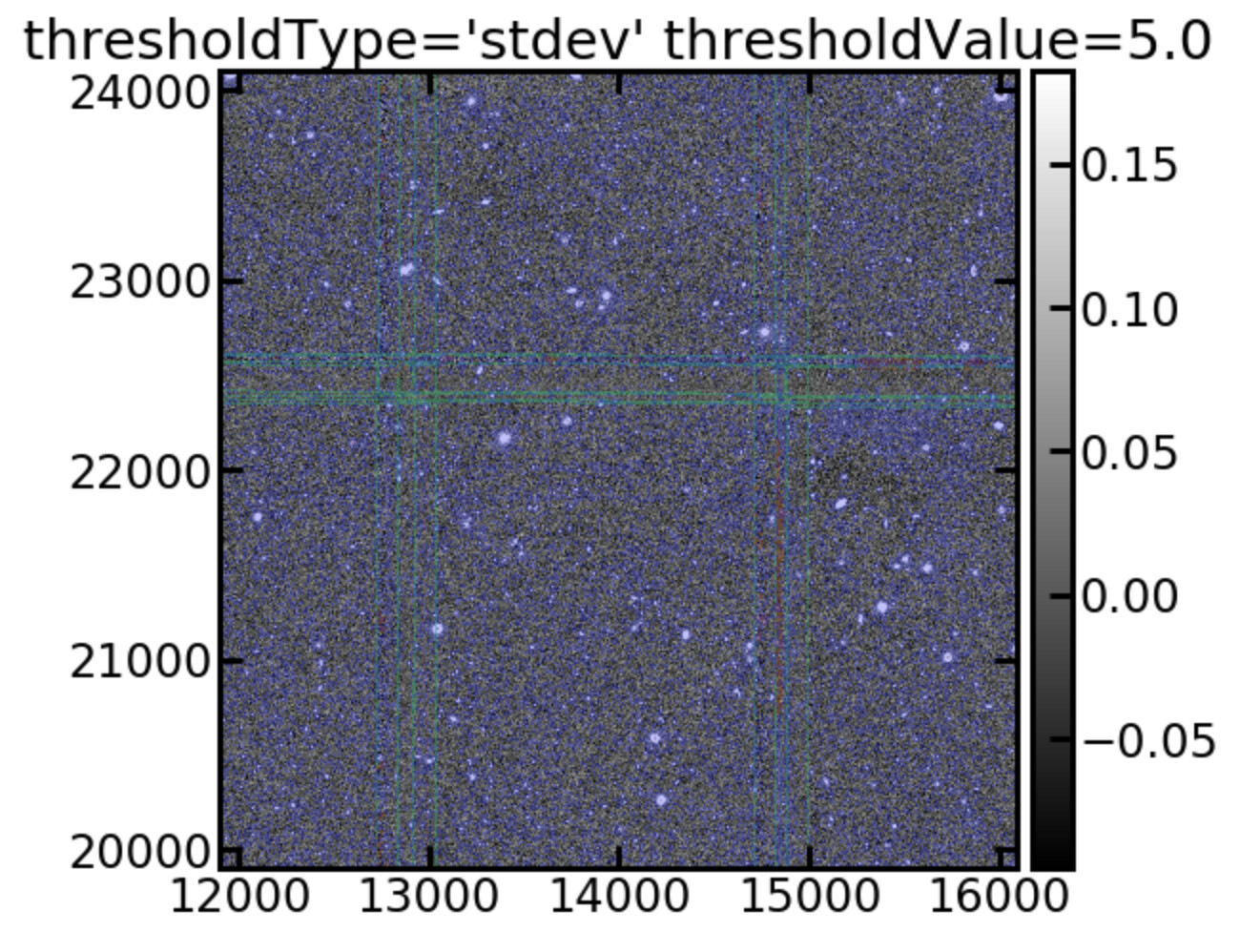
Finally, it might be that we have a more fundamental problem with the variance plane. During the detectCoaddSources it appears that the variance plane is being scaled by a factor of 0.1:
coaddDriver.detectCoaddSources.scaleVariance INFO: Renormalizing variance by 0.099319
coaddDriver.detectCoaddSources.detection INFO: Applying temporary wide background subtraction
coaddDriver.detectCoaddSources.detection INFO: Detected 2012 positive peaks in 1775 footprints to 5 sigma
coaddDriver.detectCoaddSources.detection.skyObjects INFO: Added 1000 of 1000 requested sky sources (100%)
coaddDriver.detectCoaddSources.detection.skyMeasurement INFO: Performing forced measurement on 1000 sources
coaddDriver.detectCoaddSources.detection INFO: Modifying configured detection threshold by factor 0.300488 to 3.004881
coaddDriver.detectCoaddSources.detection INFO: Detected 4432 positive peaks in 3513 footprints to 3.00488 sigma
coaddDriver.detectCoaddSources.detection INFO: Detected 5104 positive peaks in 3678 footprints to 3.00488 sigma
coaddDriver.detectCoaddSources.detection.skyObjects INFO: Added 1000 of 1000 requested sky sources (100%)
coaddDriver.detectCoaddSources.detection.skyMeasurement INFO: Performing forced measurement on 1000 sources
coaddDriver.detectCoaddSources.detection INFO: Tweaking background by -0.000661 to match sky photometry
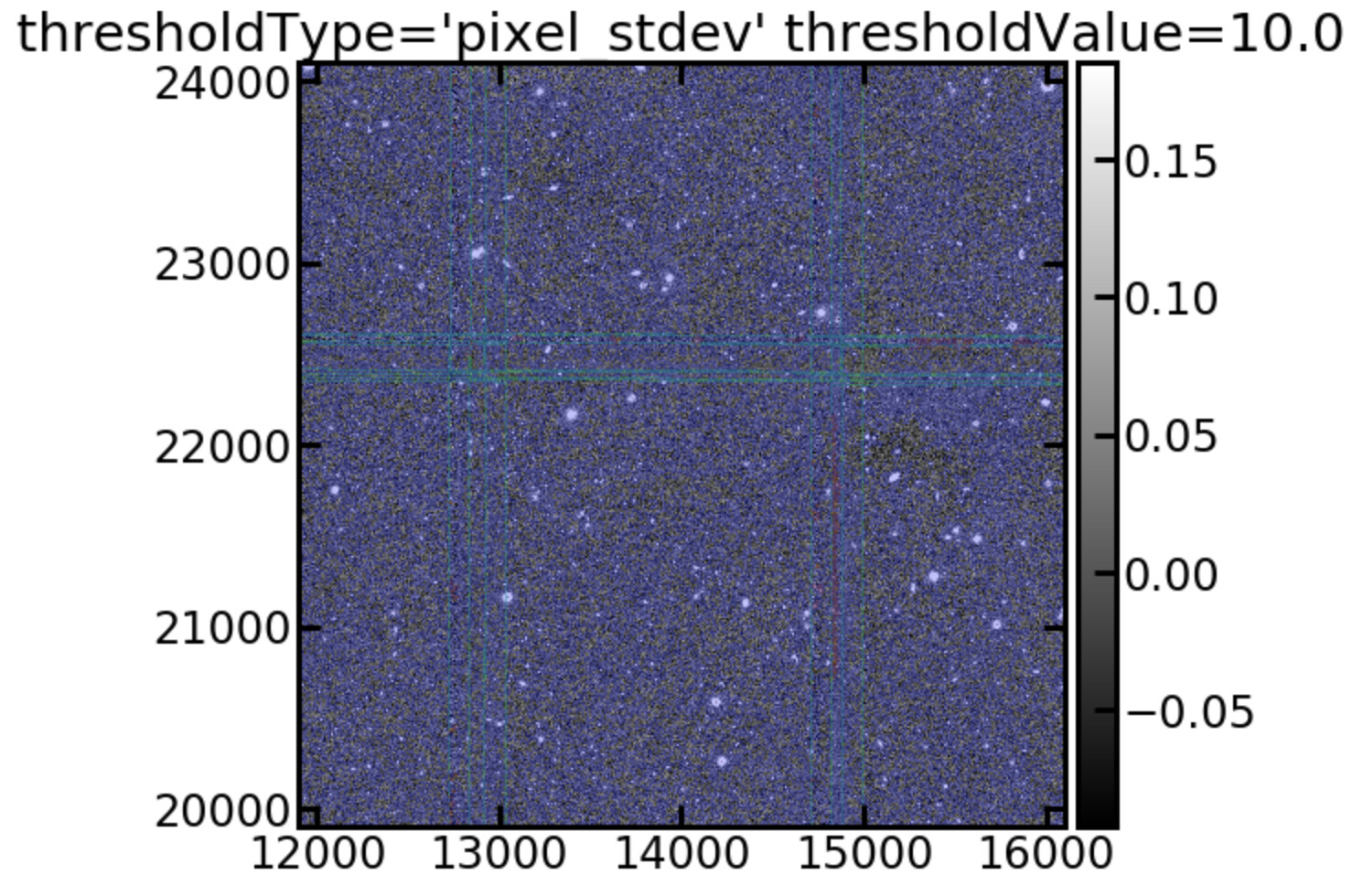
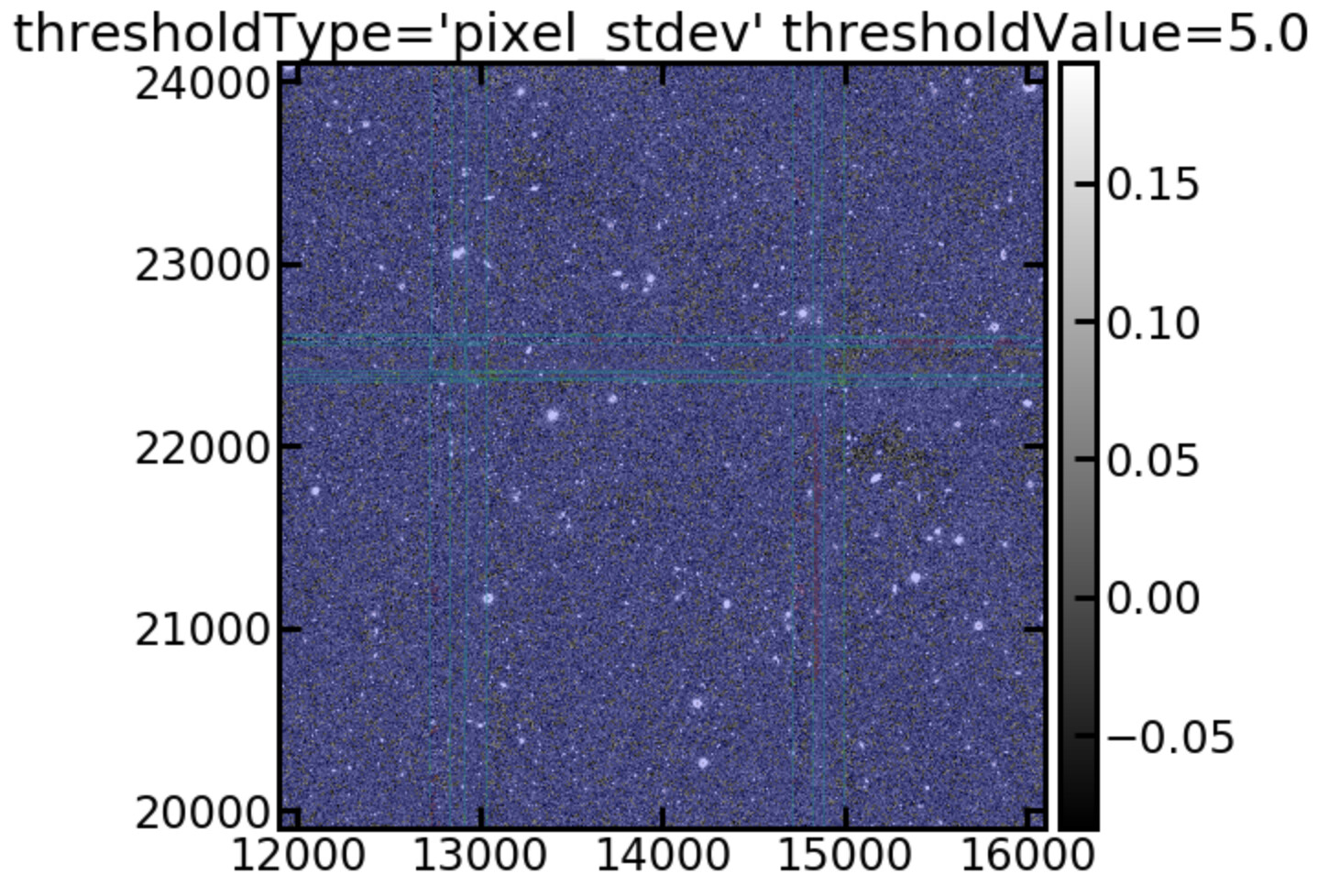
This seems high. Perhaps we should switch off the variance scaling? In a previous post I discussed how we use image standard deviation to determine source detection because the pixel based standard deviation was yielding too many sources. Is there an obvious reason why the scale variance task would fail when using non-native pixel scales. Another issue with our runs is that we are using six exposure stacks as input images instead of raw exposures because the single exposures were not deep enough to identify enough calibration stars. Does the variance scaling propagate through to the measurements? I am curious that following the variance scaling the detection threshold is also scaled by a similar factor (sqrt(0.1)~0.3).
Many thanks for reading this detailed question.
Raphael.